Automattic, la empresa detrás de WordPress y Tumblr, está planeando discusiones para monetizar el contenido de los usuarios mediante la venta de sus datos a empresas de inteligencia artificial, incluyendo MidJourney y OpenAI. Estos datos de las plataformas de blogging Tumblr y WordPress.com se utilizarán para entrenar modelos de IA.
Aunque los detalles de la transacción aún no están claros, esta noticia ha generado preocupaciones entre los usuarios respecto al posible uso indebido de su contenido privado en las dos plataformas de blogging. Además, 404 Media sugiere que ha habido conflictos internos dentro de Automattic ya que el contenido recolectado incluye datos privados que no estaban destinados a ser retenidos dentro de la empresa.
En respuesta a las reacciones negativas, Automattic planea introducir una nueva función que permitirá a los usuarios optar por no compartir sus datos para el entrenamiento de IA. En una publicación de blog, la empresa reafirma su compromiso de proporcionar a los usuarios de Tumblr y WordPress un mayor control sobre su contenido. Se menciona el lanzamiento de un ajuste para "desalentar la exploración por parte de las empresas de IA", explicando que las principales plataformas de exploración de IA están bloqueadas de forma predeterminada.
El problema del uso del contenido de blogs por parte de empresas que desarrollan modelos de IA no se limita a las plataformas administradas por Automattic. Tanto OpenAI como Google utilizan robots rastreadores para recopilar información de todos los sitios web para entrenar modelos de inteligencia artificial. El proceso es similar a la recopilación de datos por parte de los motores de búsqueda.
¿Cómo puedes bloquear que OpenAI y Gemini (Bard) obtengan datos de tu blog?
Si eres propietario de un blog o sitio web y no quieres que sus datos se utilicen para entrenar los modelos de inteligencia artificial de OpenAI y Gemini, puedes bloquear el acceso de los robots (rastreadores) al contenido. Esta restricción se puede implementar a través del archivo robots.txt.
OpenAI Crawlers
User-agent: GPTBot
Disallow: /Gemini Crawlers
User-agent: Google-Extended
Disallow: /Después de guardar el archivo robots.txt con las nuevas líneas, ve a Google Console en: Configuración > robots.txt > haz clic en el menú con los tres puntos, haz clic en "Solicitar un nuevo rastreo".
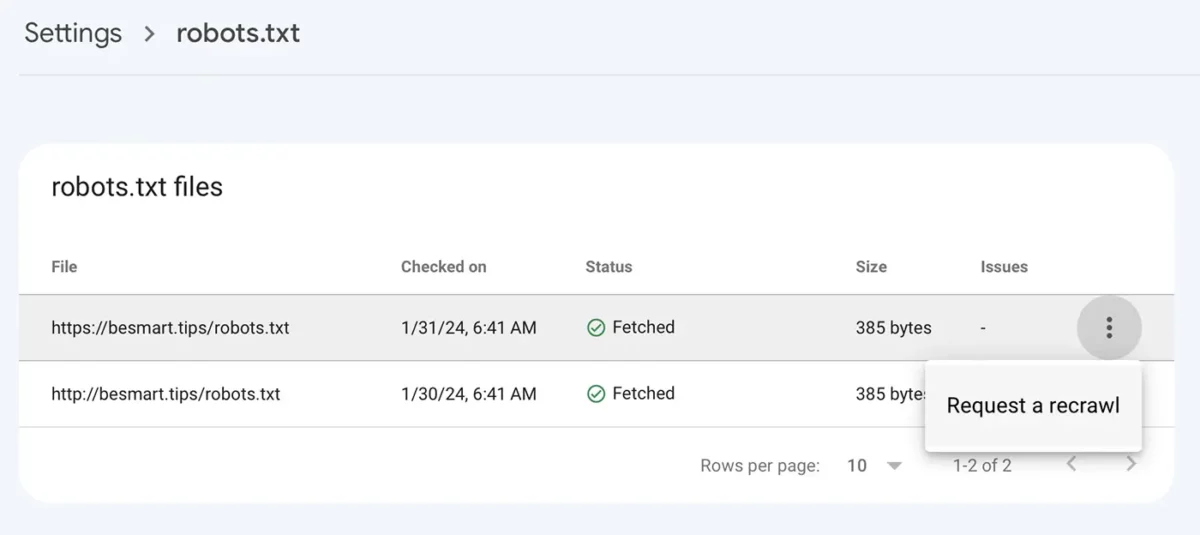
Relacionado: GPT-5 y el nuevo rastreador web GPTBot desarrollado por OpenAI.
Para los usuarios de Tumblr y WordPress, el acceso a la recuperación de datos de los blogs por parte de OpenAI u otras empresas que desarrollan inteligencia artificial puede bloquearse a través de las herramientas proporcionadas por Automattic.